



2025-06-28
OB视讯助力云南怒江州12所乡村学校完成专递课堂设备部署
技术团队历时45天,跨越怒江峡谷地带的险峻山路,完成了12所偏远乡村学校的设备安装与调试,惠及3200余名师生。
阅读全文覆盖全学段、全场景的教育视讯产品矩阵,从乡村教学点到城市重点校,一站满足

集成了AI人脸识别自动跟踪、语音激励切换、多机位智能导播的完整录播解决方案。设备开机即用,无需专业技术人员值守,教师可一键启动录制。系统在2024年完成第三代迭代,新增板书增强识别算法,可将黑板书写内容以画中画形式叠加到最终视频中,回放时板书清晰可见。支持与学校现有教务系统对接,录制的课程自动归档至校本资源库。

针对中学理化生实验教学中高危操作多、器材损耗大、课时紧张等痛点,OB视讯研发了基于WebGL技术的虚拟仿真实验平台。系统内置超过200个标准化实验项目,覆盖初高中主流教材。学生在虚拟环境中可反复操作,系统自动记录实验步骤并生成操作报告。2025年新增的多人协同模式支持6名学生同时在虚拟实验室中分工协作,模拟真实分组实验场景。

从演播室声学装修设计到设备采购安装调试,OB视讯提供校园电视台交钥匙工程。核心设备包括4讯道高清切换台、虚拟抠像系统、专业级采访麦克风套装和LED柔光灯组。整套系统简化了传统广电设备的复杂操作逻辑,学生经过2天培训即可独立完成校园新闻录播和直播任务。目前全国已有超过160所学校使用OB视讯校园电视台方案常态化运营。

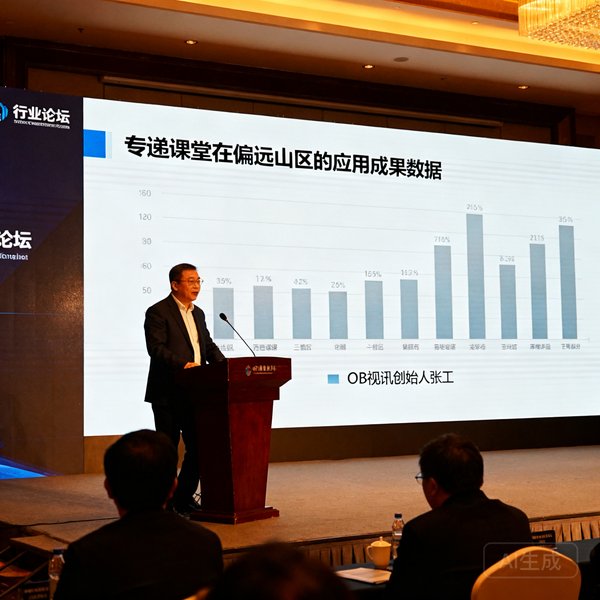
专递课堂是OB视讯投入研发资源最多的产品线之一,旨在解决偏远地区师资不足、课程开不齐的难题。设备采用工业级嵌入式架构,功耗低于35W,在电压不稳定的农村电网环境下仍能稳定运行。内置的智能缓存和断点续传机制确保在网络波动时教学不中断。搭配OB视讯自研的课堂互动数据分析平台,教育主管部门可实时查看各教学点的出勤率、互动频次和课程完成情况。
每一组数字背后,都是学校和教育部门的真实选择
合作学校覆盖全国
截至2025年7月省级行政区全覆盖
含自治区及直辖市设备稳定运行率
180天连续监测数据专业团队成员
研发占比超过40%累计录制课程视频数
专递课堂受益教学点
项自主知识产权专利

2013年5月,三位毕业于北京邮电大学通信工程专业的年轻人在中关村一间不足40平米的办公室里创办了OB视讯。创始团队中的张工曾在云南怒江支教两年,亲眼目睹了山区学校因为缺老师、缺设备而导致音乐课和美术课常年停摆的状况。这段经历成为OB视讯创立之初最朴素的原动力——用视讯技术连接城乡课堂,让每一个孩子都能听到优质课程。
发展历程:公司成立前三年,团队主要承接高校精品课程录制项目,积累了扎实的视音频处理技术基础。2016年,OB视讯推出第一代智慧录播一体机,当年便获得教育部教育装备研究与发展中心的技术认证。2018年,公司中标云南省"专递课堂"省级试点项目,在滇西7个县部署了210套设备,这是OB视讯从城市走向乡村的关键转折点。截至2025年,公司已发展成为拥有180余名员工、其中研发人员占比超过40%的专业教育视讯企业。
团队实力:核心研发团队来自华为、海康威视、科大讯飞等企业,在视频编解码、AI视觉算法和流媒体传输领域拥有平均8年以上的实战经验。公司在北京设立研发中心,在深圳设有硬件生产品控基地,在成都、武汉、西安设有区域技术支持中心,确保全国范围内的项目能够48小时内响应。
发展愿景:OB视讯不追求做最大的教育装备企业,而是希望成为最懂一线教学场景的视讯技术公司。未来三年,公司计划将专递课堂设备覆盖到全国5000个以上偏远教学点,同时加大虚拟仿真实验系统的学科覆盖面,让技术真正服务于教育公平和教学质量提升。
不同学段的教学场景差异巨大,我们提供精准匹配的视讯方案
针对小学生注意力集中时间短的特点,录播系统预设"趣味互动模式",自动在录播画面中叠加动画提示框和鼓励性字幕。专递课堂设备配备一键求助按钮,低年级学生也能轻松操作。系统内置课堂行为分析模块,帮助教师了解每位学生的参与度变化曲线。
中学方案以虚拟仿真实验视讯系统为核心特色,重点解决理化生实验教学中的安全风险和器材消耗问题。录播教室支持分组实验过程的同步录制,教师可回放任一小组的操作细节进行点评。校园电视台方案在此阶段还可与社团活动结合,培养学生的媒介素养和团队协作能力。
面向高校和职业院校,提供大规模阶梯教室的智能录播方案,支持200人以上教室的多机位无死角覆盖。虚拟仿真系统扩展至工科实训领域,如汽车维修仿真、数控机床操作模拟等。同时提供与学校现有 LMS(学习管理系统)的数据对接服务,录播资源可直接推送至学生端。
来自一线教师和学校管理者的使用评价

云南怒江州兰坪县石登乡中心完小 · 语文教师
"我们学校距离县城80多公里,以前音乐课只能放录音。2023年装了OB视讯的专递课堂设备后,孩子们每周都能跟着县城最好的音乐老师学唱歌。设备操作很简单,我50多岁了也能学会,按一个键就开始同步上课。最感动的是有次网络断了,设备自动缓存了整节课,网络恢复后完整上传,啥也没丢。"

四川成都七中万达学校 · 副校长
"我们学校的校园电视台从2022年9月开播至今,学生团队已经制作了超过80期校园新闻节目。OB视讯的设备稳定性非常好,两年来没有出现过一次重大故障。导播切换台的学习曲线很平缓,我们的学生记者团高一新生经过一个周末的培训就能上手操作。现在校园电视台已经成为学校对外展示的重要窗口。"
一群真正懂教育、懂技术的实干者
创始人 & CEO
北邮通信工程硕士,前华为视频技术高级工程师。2011-2013年在云南支教期间萌生创业想法。主导公司产品战略方向,亲自带队完成多个省级专递课堂项目的技术方案设计。

联合创始人 & CTO
前海康威视嵌入式开发主管,拥有9项视频编解码相关发明专利。带领40余人研发团队,主导设计了OB视讯全系列产品的核心架构,尤其在低带宽流媒体传输技术上有多项突破。

教育研究总监
北师大教育学博士,曾在教育部基础教育课程教材发展中心工作6年。负责将一线教学需求转化为产品功能设计,确保OB视讯的每一款产品都真正贴合课堂实际场景。
关于OB视讯产品和服务的常见疑问
填写以下信息,我们的教育解决方案专家将在24小时内与您联系,为您提供针对学校实际情况的定制化视讯方案。
了解OB视讯的最新项目进展与行业观察
技术团队历时45天,跨越怒江峡谷地带的险峻山路,完成了12所偏远乡村学校的设备安装与调试,惠及3200余名师生。
阅读全文
新版本支持6名学生同时在线协作完成实验,系统自动记录每位学生的操作步骤并生成个人实验报告,已在12所学校完成试点测试。
阅读全文展会上接待了来自17个省份的教育局代表和学校负责人,现场签约意向金额突破800万元,专递课堂设备成为最受关注的展品之一。
阅读全文为期3天的培训涵盖录播系统操作、视频后期剪辑和课堂数据分析等内容,参训教师来自全国32所学校,培训满意度达到98.6%。
阅读全文即日起至2025年9月30日,预约即可获得OB视讯技术团队上门演示服务,现场体验智慧录播教室的实际效果,还有机会获得免费试用30天的名额。